으* 본 포스팅은 머신러닝 교과서를 참조하여 작성되었습니다!
3.3 로지스틱 회귀 모델을 사용한 클래스 확률 모델링
퍼셉트론 규칙은 머신 러닝 분류 알고리즘을 배우기에 간단하고 좋은 모델이지만 가장 큰 단점은 클래스가 선형적으로 구분되지 않을 때 수렴할 수 없다.
여전히 간단하지만 선형 이진 분류 문제에 더 강력한 다른 알고리즘은 로지스틱 회귀(logistic Regression)을 살펴보자.
* 이름이 회귀이지만 로지스틱 회귀는 회귀가 아니라 분류모델이다!
3.3.1 로지스틱 회귀의 이해와 조건부 확률
오즈비(odds ratio) : 오즈는 특정 이벤트가 발생할 확률이다.

- logit 함수는 0과 1 사이의 입력값을 받아 실수 범위 값으로 반환한다.
- 이 함수를 로지스틱 시그모이드 함수(logistic sigmoid function) 이라고 한다. 함수 모양이 S자 형태를 띠기 때문에 간단하게 줄여서 시그모이드 함수라고도 한다.
그렇다면 시그모이드 함수를 그려보자

- 이 시그모이드 함수는 실수 입력 값을 [0, 1]사이의 값으로 반환하고 중간은 0.5이다.


- 실제로 클래스 레이블을 예측하는 것 외에 클래스에 소속될 확률(임계 함수를 적용하기 전 시그모이드 함수 출력)을 추정하는 것이 유용한 애플리케이션도 많다.
3.3.2 로지스틱 비용 함수의 가중치 학습

샘플이 하나인 경우 J(w) 값에 대한 분류 비용을 그려보자.

- 클래스 1에 속한 샘플을 정확히 예측하면 비용이 0에 가까워진다(실선)
- 클래스 0에 속한 샘플을 y = 0으로 정확히 예측하면 y축의 비용이 0에 가까워진다.(점선)
>> 예측이 잘못되면 비용이 무한대가 된다. 잘못된 예측에 점점 더 큰 비용을 부여한다는 점이 중요하다.
3.3.3 아달린 구현을 로지스틱 회귀 알고리즘으로 변경
로지스틱 회귀를 구현하려면 아달린 구현에서 비용 함수 J를 새로운 비용 함수로 바꾸면 된다.
선형 활성화 함수를 시그모이드 활성화로 바꾸고 임계 함수가 클래스 레이블 -1과 1이 아니고 0과 1을 반환하도록 변경한다.
class LogisticRegressionGD(object):
"""경사 하강법을 사용한 로지스틱 회귀 분류기
매개변수
------------
eta : float
학습률 (0.0과 1.0 사이)
n_iter : int
훈련 데이터셋 반복 횟수
random_state : int
가중치 무작위 초기화를 위한 난수 생성기 시드
속성
-----------
w_ : 1d-array
학습된 가중치
cost_ : list
에포크마다 누적된 로지스틱 비용 함수 값
"""
def __init__(self, eta=0.05, n_iter=100, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
"""훈련 데이터 학습
매개변수
----------
X : {array-like}, shape = [n_samples, n_features]
n_samples 개의 샘플과 n_features 개의 특성으로 이루어진 훈련 데이터
y : array-like, shape = [n_samples]
타깃값
반환값
-------
self : object
"""
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
net_input = self.net_input(X)
output = self.activation(net_input)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
# 오차 제곱합 대신 로지스틱 비용을 계산합니다.
cost = -y.dot(np.log(output)) - ((1 - y).dot(np.log(1 - output)))
self.cost_.append(cost)
return self
def net_input(self, X):
"""최종 입력 계산"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, z):
"""로지스틱 시그모이드 활성화 계산"""
# 대신 from scipy.special import expit; expit(z) 을 사용할 수 있습니다.
return 1. / (1. + np.exp(-np.clip(z, -250, 250)))
def predict(self, X):
"""단위 계단 함수를 사용하여 클래스 레이블을 반환합니다"""
return np.where(self.net_input(X) >= 0.0, 1, 0)
# 다음과 동일합니다.
# return np.where(self.activation(self.net_input(X)) >= 0.5, 1, 0)
# Iris-setosa 와 Iris-versicolor 붓꽃만 가지고 로지스틱 회귀 구현을 해보자
X_train_01_subset = X_train[(y_train == 0) | (y_train == 1)]
y_train_01_subset = y_train[(y_train == 0) | (y_train == 1)]
lrgd = LogisticRegressionGD(eta=0.05,
n_iter = 1000,
random_state = 1)
lrgd.fit(X_train_01_subset, y_train_01_subset)
plot_decision_regions(X = X_train_01_subset,
y = y_train_01_subset,
classifier=lrgd)
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()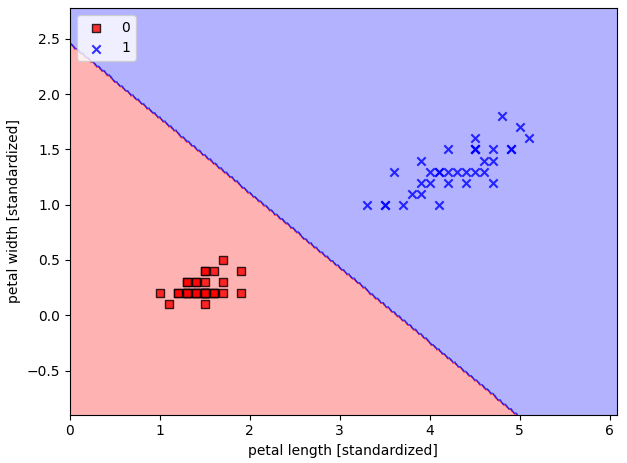
3.3.4 사이킷런을 사용하여 로지스틱 회귀 모델 훈련
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=100.0, random_state=1)
lr.fit(X_train_std, y_train)
plot_decision_regions(X_combined_std, y_combined,
classifier=lr, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('images/03_06.png', dpi=300)
plt.show()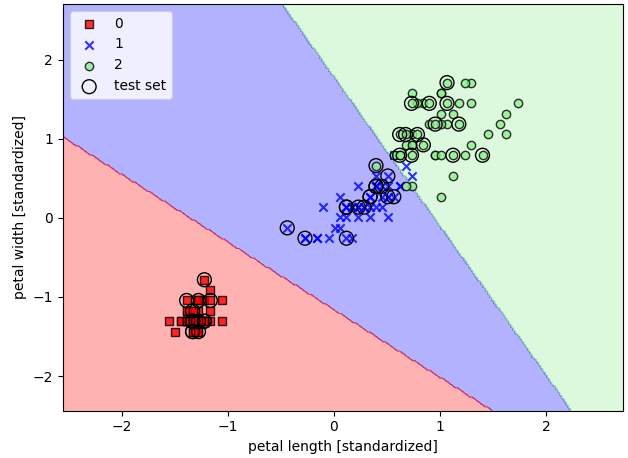
3.3.5 규제를 사용하여 과대적합 피하기
과대적합(overfitting)은 머신 러닝에서 자주 발생하는 문제이다. 모델이 훈련 데이터로는 잘 동작하지만 본 적 없는 데이터(테스트 데이터)로는 잘 일반화되지 않는 현상이다.
과소적합(underfitting) 은 훈련 데이터에 있는 패턴을 감지할 정도로 충분히 모델이 복잡하지 않다는 것을 의미한다. 이 때문에 새로운 데이터에서도 성능이 낮을 것이다.
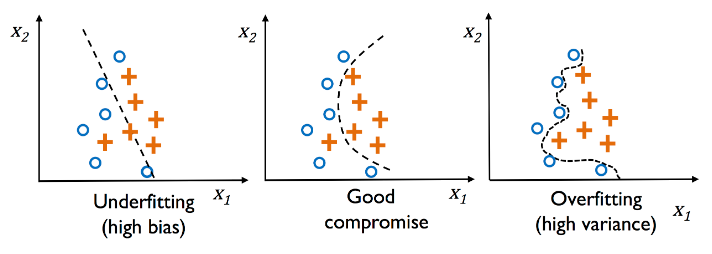
* 편향-분산 트레이드오프란?
- 일반적으로 '높은 분산'은 과대적합에 비례하고, '높은 편향'은 과소적합에 비례한다는 뜻이다.
- 머신 러닝에서 '분산' 은 모델을 여러 번 훈련했을 때 특정 샘플에 대한 예측의 일관성(또는 변동성)을 측정한다.
- '편향'은 다른 훈련 데이터셋에서 여러 번 훈련했을 때 예측이 정확한 값에서 얼마나 벗어나있는지 측정한다.
규제(regularization)은 공선성(collinearity)(특성 간의 높은 상관관계)을 다루거나 데이터에서 잡음을 제거하여 과대적합을 방지할 수 있는 매우 유용한 방법이다.
규제는 과도한 파라미터(가중치) 값을 제한하기 위해 추가적인 정보(편향)을 주입하는 개념이다.

- 가장 널리 사용하는 규제는 L2 규제이다.
- 규제 하이퍼파라미터 값을 증가시키면 규제 강도가 높아진다.
- 3.3.4 의 코드에서 매개변수 C는 규제 하이퍼파라미터의 역수이다.
결과적으로 C의 값을 감소시키면 규제 강도가 증가한다.
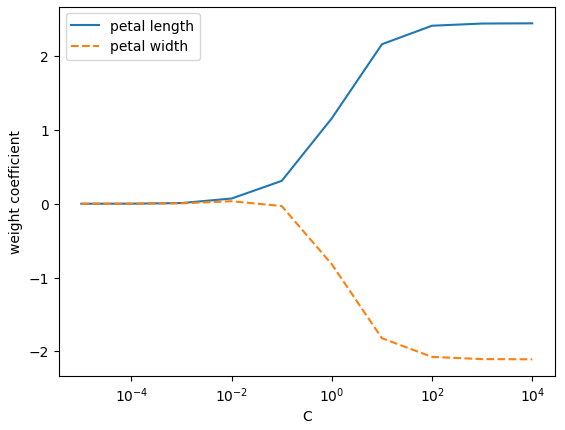
weights, params = [], []
for c in np.arange(-5, 5):
lr = LogisticRegression(C = 10.**c, random_state = 1, multi_class='ovr')
lr.fit(X_train_std, y_train)
weights.append(lr.coef_[1])
params.append(10. ** c)
weights = np.array(weights)
plt.plot(params, weights[:, 0],
label = 'petal length')
plt.plot(params, weights[:, 1], linestyle='--',
label = 'petal width')
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.legend(loc='upper left')
plt.xscale('log')
plt.show()- 이 코드를 실행하면 역 규제 매개변수 C의 값을 바꾸면서 열 개의 로지스틱 회귀 모델을 훈련한다.
- 결과 그래프에서 보듯 매개변수 C가 감소하면 가중치 절댓값이 줄어든다. 즉, 규제 강도가 증가한다.
이번 포스팅에서는 로지스틱 회귀모델을 직접 구현해보고, 사이킷런을 사용하여 로지스틱 회귀모델을 사용해 보았다. 또 데이터의 과대적합, 과소적합을 예방하는 규제에 대해 배웠다.
'소소하지만 소소하지 않은 개발 공부 > 머신 러닝 교과서' 카테고리의 다른 글
| Chapter3.7 k-최근접 이웃: 게으른 학습 알고리즘, 머신러닝교과서, python (1) | 2022.11.29 |
|---|---|
| Chapter 3.6 결정 트리 학습, 머신러닝교과서, pyhon (0) | 2022.11.29 |
| Chapter 3.4 서포트 벡터 머신을 사용한 최대 마진 분류, 머신러닝교과서, python (0) | 2022.11.25 |
| Chapter3 머신러닝 교과서, python (0) | 2022.11.22 |
| 머신러닝 교과서, 2.2, python (0) | 2022.11.18 |