* 본 포스팅은 머신러닝교과서를 참조하여 작성되었습니다.
* https://github.com/rickiepark/python-machine-learning-book-3rd-edition
GitHub - rickiepark/python-machine-learning-book-3rd-edition: <머신 러닝 교과서 3판>의 코드 저장소
<머신 러닝 교과서 3판>의 코드 저장소. Contribute to rickiepark/python-machine-learning-book-3rd-edition development by creating an account on GitHub.
github.com
생성적 적대 신경망(Generative Adversarial Network, GAN)의 주요한 목적은 훈련 데이터셋과 동일한 분포를 가진 새로운 데이터를 합성하는 것이다. 따라서 GAN의 원본 형태는 레이블 데이터가 필요하지 않으므로 머신 러닝 작업 중 비지도 학습 범주로 간주된다.

밑바닥부터 GAN 모델 구현
생성자와 판별자 신경망 구현

첫 번째 GAN 모델의 생성자와 판별자를 한 개 또는 그 이상의 은닉층으로 가진 완전 연결 신경망으로 구현한다.
이 모델의 각 은닉층에는 LeakyReLU 활성화 함수를 사용한다. 렐루(ReLU)를 사용하면 희소한 그레이디언트가 발생하기 때문에 입력 값 전 범위에 걸쳐 그레이디언트가 필요할 때는 적합하지 않기 때문이다. 판별자 신경망에서 각 은닉층 다음에는 드롭아웃 층이 뒤따른다. 생성자의 출력층은 하이퍼볼릭 탄젠트(tanh) 활성화 함수를 사용한다.
판별자의 출력층은 로짓을 계산하기 위해 활성화 함수를 가지지 않는다(즉, 선형 활성화 함수를 사용한다). 아니면 확률을 출력으로 얻기 위해 시그모이드 활성화 함수를 사용할 수 있다.
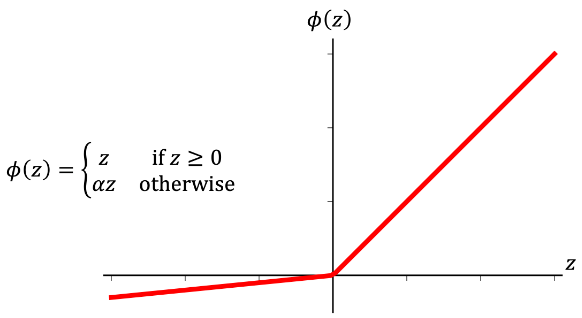
두 신경망을 위해 두 개의 헬퍼 함수를 정의한다. 이 함수는 케라스 Sequential 클래스로 모델을 만들고 앞서 언급한 층을 추가한다.
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
import matplotlib.pyplot as plt
## 생성자 함수를 정의한다:
def make_generator_network(
num_hidden_layers=1,
num_hidden_units=100,
num_output_units=784):
model = tf.keras.Sequential()
for i in range(num_hidden_layers):
model.add(
tf.keras.layers.Dense(units=num_hidden_units, use_bias=False))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dense(units=num_output_units, activation='tanh'))
return model
## 판별자 함수를 정의한다:
def make_discriminator_network(
num_hidden_layers=1,
num_hidden_units=100,
num_output_units=1):
model = tf.keras.Sequential()
for i in range(num_hidden_layers):
model.add(
tf.keras.layers.Dense(units=num_hidden_units))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(rate=0.5))
model.add(tf.keras.layers.Dense(units=num_output_units, activation=None))
return model
그 다음 모델을 훈련하기 위한 설정을 한다. 그다음 입력 벡터 z의 크기를 20으로 지정하고 모델 가중치를 균등 분포로 랜덤하게 초기화한다.
# MNIST 이미지가 28 X 28 이므로,
image_size = (28, 28)
z_size = 20
mode_z = 'uniform' # 'uniform' vs 'normal'
gen_hidden_layers = 1
gen_hidden_size = 100
disc_hidden_layers = 1
disc_hidden_size = 100
tf.random.set_seed(1)
gen_model = make_generator_network(
num_hidden_layers=gen_hidden_layers,
num_hidden_units=gen_hidden_size,
num_output_units=np.prod(image_size))
gen_model.build(input_shape=(None, z_size))
gen_model.summary()
disc_model = make_discriminator_network(
num_hidden_layers=disc_hidden_layers,
num_hidden_units=disc_hidden_size)
disc_model.build(input_shape=(None, np.prod(image_size)))
disc_model.summary()
훈련 데이터셋 정의
다음 단계로 MNIST 데이터셋을 로드하고 필요한 전처리 단계를 적용한다. 생성자의 출력층이 tanh 활성화 함수를 사용하기 때문에 합성된 이미지가 갖는 픽셀 값의 범위는(-1, 1)이다. 하지만 입력되는 MNIST 이미지 픽셀 범위는 [0,255] 이다. 따라서 전처리 단계에서 tf.image.convert_image_dtype 함수를 사용해서 입력 이미지 텐서의 dtype을 tf.unit8에서 tf.float32 로 바꾼다. dtype이 바뀌는 것 외에도 이 함수를 호출하면 픽셀 강도의 범위를 [0, 1]로 바꾼다. 여기에다 2를 곱하고 1을 빼서 픽셀 강도를 [-1, 1]범위로 조정한다. 또한, 랜덤한 분포를 기반으로 랜덤 벡터 z를 만든다. 그다음 전처리된 이미지와 랜덤 벡터를 튜플로 반환한다.
mnist_bldr = tfds.builder('mnist')
mnist_bldr.download_and_prepare()
mnist = mnist_bldr.as_dataset(shuffle_files=False)
def preprocess(ex, mode='uniform'):
image = ex['image']
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.reshape(image, [-1])
image = image*2 - 1.0
if mode == 'uniform':
input_z = tf.random.uniform(
shape=(z_size,), minval=-1.0, maxval=1.0)
elif mode == 'normal':
input_z = tf.random.normal(shape=(z_size,))
return input_z, image
mnist_trainset = mnist['train']
print('전처리 전: ')
example = next(iter(mnist_trainset))['image']
print('dtype: ', example.dtype, ' 최소: {} 최대: {}'.format(np.min(example), np.max(example)))
mnist_trainset = mnist_trainset.map(preprocess)
print('전처리 후: ')
example = next(iter(mnist_trainset))[0]
print('dtype: ', example.dtype, ' 최소: {} 최대: {}'.format(np.min(example), np.max(example)))
>> 전처리 전:
dtype: <dtype: 'uint8'> 최소: 0 최대: 255
전처리 후:
dtype: <dtype: 'float32'> 최소: -0.8737728595733643 최대: 0.9460210800170898
다음 코드에서 한 개의 배치를 추출하여 입력 벡터와 이미지 배열의 크기를 출력한다. 또한, GAN 모델의 전체 데이터 흐름을 이해하기 위해 생성자와 판별자의 정방향 계산을 실행해 본다.
먼저 입력 벡터 z의 배치를 생성자에 주입하여 출력 g_output을 얻는다. 이는 가짜 샘플의 배치이다. 이 배치를 판별자 모델에 주입하여 가짜 샘플의 로짓인 d_logits_fake를 얻는다. 또한, 데이터셋 객체에서 가져온 전처리된 이미지를 판별자 모델에 주입하여 진짜 이미지에 대한 로짓 d_logits_real을 얻는다.
mnist_trainset = mnist_trainset.batch(32, drop_remainder=True)
input_z, input_real = next(iter(mnist_trainset))
print('input-z -- 크기:', input_z.shape)
print('input-real -- 크기:', input_real.shape)
g_output = gen_model(input_z)
print('생성자 출력 -- 크기:', g_output.shape)
d_logits_real = disc_model(input_real)
d_logits_fake = disc_model(g_output)
print('판별자 (진짜) -- 크기:', d_logits_real.shape)
print('판별자 (가짜) -- 크기:', d_logits_fake.shape)
>> input-z -- 크기: (32, 20)
input-real -- 크기: (32, 784)
생성자 출력 -- 크기: (32, 784)
판별자 (진짜) -- 크기: (32, 1)
판별자 (가짜) -- 크기: (32, 1)
두 로짓 d_logits_fake와 d_logits_real은 모델을 훈련하는 동안 손실 함수를 계산하는 데 사용 된다.
'소소하지만 소소하지 않은 개발 공부 > 머신 러닝 교과서' 카테고리의 다른 글
| [머신러닝교과서] 1독 기념 사진촬영 (0) | 2023.02.08 |
|---|---|
| [머신러닝교과서] GAN 모델 구현하기(2) (0) | 2023.02.03 |
| [머신러닝교과서] RNN을 사용한 영화 리뷰 감성 분석(2) (0) | 2023.02.01 |
| [머신러닝교과서] RNN을 사용한 영화 리뷰 감성 분석(1) (2) | 2023.01.31 |
| [머신러닝교과서] 순차 데이터 모델링의 개념 (0) | 2023.01.31 |