[머신러닝교과서] RNN을 사용한 영화 리뷰 감성 분석(1)
* 본 포스팅은 머신러닝교과서를 참조하여 작성되었습니다.
* https://github.com/rickiepark/python-machine-learning-book-3rd-edition
GitHub - rickiepark/python-machine-learning-book-3rd-edition: <머신 러닝 교과서 3판>의 코드 저장소
<머신 러닝 교과서 3판>의 코드 저장소. Contribute to rickiepark/python-machine-learning-book-3rd-edition development by creating an account on GitHub.
github.com
감성 분석을 위해서 다대일(many-to-one) 구조의 다층 RNN을 구현할 수 있다. 머신러닝교과서에서 제공하는 movie_data 셋을 활용하여 데이터 전처리를 통해 RNN을 구현해 보자!
영화 리뷰 데이터 준비
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
import pandas as pd
import os
import gzip
import shutil
df = pd.read_csv('movie_data.csv', encoding='utf-8')
df.tail()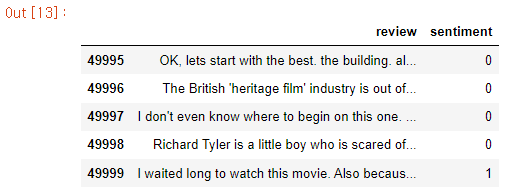
GitHub - rickiepark/python-machine-learning-book-3rd-edition: <머신 러닝 교과서 3판>의 코드 저장소
<머신 러닝 교과서 3판>의 코드 저장소. Contribute to rickiepark/python-machine-learning-book-3rd-edition development by creating an account on GitHub.
github.com
영화 리뷰 데이터셋은 해당 링크에서 다운로드 할 수 있다.
movie_data 셋을 다운받아 확인해 보니 데이터프레임 df 에는 'review'와 'sentiment' 두 개의 컬럼이 있다. 'review'는 영화 리뷰 텍스트(입력 특성)를 담고 있고 'sentiment'는 예측하려는 타깃 레이블이다.
영화 리뷰 텍스트는 단어의 시퀀스 이다. RNN모델을 만들어 각 시퀀스를 긍정적(1) 또는 부정적(0)인 리뷰로 분류해보자.
RNN 모델에 데이터를 주입하기 전에 몇 가지 전처리 단계를 적용해야 한다.
- 텐서플로 데이터셋 객체를 만들고 훈련, 테스트, 검증 데이터셋으로 나눈다.
- 훈련 데이터셋에 있는 고유한 단어를 찾는다.
- 고유한 단어를 고유한 정수로 매핑하고 리뷰 텍스트를 정수(고유 단어의 인덱스) 배열로 인코딩한다.
- 모델에 입력하기 위해 데이터셋을 미니 배치로 나눈다.
1. 단계
첫 번째 단계이다. 데이터 프레임에서 텐서플로 데이터셋을 만든다.
## 1단계 : 데이터셋 만들기
target = df.pop('sentiment')
ds_raw = tf.data.Dataset.from_tensor_slices((df.values, target.values))
## 확인:
for ex in ds_raw.take(3):
tf.print(ex[0].numpy()[0][:50], ex[1])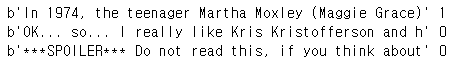
이제 훈련, 테스트, 검증 데이터셋으로 나눌 수 있다. 전체 데이터셋은 5만 개의 샘플을 담고 있다. 처음 2만 5000개의 샘플은 평가를 위해 떼어 놓는다. 그 다음 2만 개의 샘플은 훈련에 사용하고 5,000개의 샘플은 검증에 사용한다.
# 일정한 결과값을 얻기 위한 seed값 설정
tf.random.set_seed(1)
ds_raw = ds_raw.shuffle(50000, reshuffle_each_iteration=False)
ds_raw_test = ds_raw.take(25000)
ds_raw_train_valid = ds_raw.skip(25000)
ds_raw_train = ds_raw_train_valid.take(20000)
ds_raw_valid = ds_raw_train_valid.skip(20000)
2단계
신경망의 입력으로 데이터를 준비하기 위해 단계 2~3에서 언급한 것처럼 숫자 값으로 인코딩 해야 한다. 이렇게 하기 위해 먼저 훈련 데이터셋에서 고유한 단어(토큰)을 찾는다. 데이터셋을 사용하여 고유한 토큰을 찾을 수 있지만 파이썬 표준 라이브러리에 있는 collections 패키지의 Counter 클래스를 사용하는 것이 효율적이다.
다음 코드에서 Counter 객체(token_counts)를 만들어 고유한 단어의 빈도를 수집한다. 텍스트를 단어(또는 토큰)로 나누려면 tensorflow_datasets 패키지가 제공하는 Tokenizer 클래스를 사용할 수 있다.
## 2단계: 고유 토큰(단어) 찾기
from collections import Counter
tokenizer = tfds.deprecated.text.Tokenizer()
token_counts = Counter()
for example in ds_raw_train:
tokens = tokenizer.tokenize(example[0].numpy()[0])
token_counts.update(tokens)
print('어휘 사전 크기:', len(token_counts))
>> 어휘 사전 크기: 87007
3단계
그 다음 각각의 고유 단어를 고유 정수로 매핑한다. 파이썬 딕셔너리를 사용하여 수동으로 처리할 수 있다. 키는 고유 토큰(단어)이고 키에 매핑된 값은 고유한 정수이다. 하지만 tensorflow_datasets 패키지는 이런 매핑과 전체 데이터셋을 인코딩할 수 있는 TokenTextEncoder 클래스를 제공한다. 먼저 고유한 토큰을 전달하여 TokenTextEncoder 클래스로 encoder 객체를 만든다(token_counts는 토큰과 횟수를 포함하고 있지만 여기서는 횟수가 필요하지 않으므로..무시). encoder.encode() 메서드를 호출하여 입력 텍스트를 정수 리스트로 변환한다.
## 3단계: 고유 토큰을 정수로 인코딩하기
encoder = tfds.deprecated.text.TokenTextEncoder(token_counts)
example_str = 'This is an example!'
print(encoder.encode(example_str))
>> [232, 9, 270, 1123]검증 데이터와 테스트 데이터에 있는 토큰이 훈련 데이터에 없다면 매핑되지 않을 수 있다.q개(TokenTextEncoder에 전달한 token_counts의 크기, 여기서는 8만 7007개)의 토큰이 있고 이전에 본 적이 없으며 token_counts에 포함되지 않은 모든 토큰은 정수 q+1에 할당된다. 다른 말로 하면 인덱스 q+1이 알려지지 않은 단어를 위해 예약된다. 예약된 또 다른 값은 정수 0이다. 시퀸스 길이를 조절하기 위한 용도로 사용된다.
데이터셋 객체의 map() 메서드를 사용하여 다른 변환을 적용하듯이 데이터셋에 있는 각 텍스트를 변환할 수 있다. 하지만 여기에는 문제가 있다. 텍스트 데이터가 텐서 객체에 들어가 있어 즉시 실행 모드에서 텐서의 numpy()메서드로 참조할 수 있다. 하지만 map() 메서드로 변환하는 동안에는 즉시 실행이 비활성화된다. 이 문제를 해결하기 위해 두 개의 함수를 정의한다.
## 3-A단계: 변환을 위한 함수 정의
def encode(text_tensor, label):
text = text_tensor.numpy()[0]
encoded_text = encoder.encode(text)
return encoded_text, label
## 3-B단계: 함수를 TF 연산으로 변환하기
def encode_map_fn(text, label):
return tf.py_function(encode, inp=[text, label], Tout=(tf.int64, tf.int64))
ds_train = ds_raw_train.map(encode_map_fn)
ds_valid = ds_raw_valid.map(encode_map_fn)
ds_test = ds_raw_test.map(encode_map_fn)
#샘플의 크기 확인하기:
tf.random.set_seed(1)
for example in ds_train.shuffle(1000).take(5):
print('시퀀스 길이', example[0].shape)
지금까지 단어 시쿠니슬르 정수 시퀀스로 변환했다. 하지만 여전히 해결할 문제가 있는데 시퀀스 길이가 다르다는 것이다.
일반적으로 RNN은 다른 길이의 시퀀스를 다룰 수 있지만 미니 배치에 있는 시퀀스는 효율적으로 텐서에 저장하기 위해 동일한 길이가 되어야 한다.
크기가 다른 원소를 가진 데이터셋을 미니 배치로 나누기 위해 텐서플로는 (batch() 대신) padded_batch() 메서드를 제공한다. 이 메서든느 하나의 배치에 포함되는 모든 원소를 자동으로 0으로 패딩하여 배치에 있는 모든 시퀀스가 동일한 길이가 되도록 만든다.
실제 예시로 확인해 보자! 훈련 데이터셋에서 크기가 8인 작은 데이터셋 ds_train을 만든다. 그리고 batch_size=4로 padded_batch() 메서드를 적용해 보자. 미니 배치에 들어가기 전에 개별 원소의 길이와 만들어진 미니 배치의 차원을 출력한다.
## 일부 데이터 추출하기
ds_subset = ds_train.take(8)
for example in ds_subset:
print('개별 샘플 크기:', example[0].shape)
>> 개별 샘플 크기: (119,)
개별 샘플 크기: (688,)
개별 샘플 크기: (308,)
개별 샘플 크기: (204,)
개별 샘플 크기: (326,)
개별 샘플 크기: (240,)
개별 샘플 크기: (127,)
개별 샘플 크기: (453,)
## 배치 데이터 만들기
ds_batched = ds_subset.padded_batch(
4, padded_shapes=([-1], []))
for batch in ds_batched:
print('배치 차원:', batch[0].shape)
>> 배치 차원: (4, 688)
배치 차원: (4, 453)출력된 텐서 크기에서 알 수 있듯 첫 번째 배치의 열 개수(즉, .shape[1])는 688이다. 처음 네 개의 샘플이 하나의 배치가 되었고 이 샘플 중에 가장 큰 크기를 사용했다. 다시 말하면 이 배치에 있는 세 개의 다른 샘플을 이 크기에 맞도록 필요한 만큼 패딩을 추가한다. 비슷하게 두 번째 배치의 열 크기는 다음 네 개의 샘플 중에 가장 큰 크기인 453이다. 여기서도 최대 길이보다 작은 다른 샘플에 패딩을 추가했다.
세 개의 데이터셋을 모두 배치 크기 32의 미니 배치로 나눈다.
train_data = ds_train.padded_batch(32, padded_shapes=([-1], []))
valid_data = ds_valid.padded_batch(32, padded_shapes=([-1], []))
test_data = ds_test.padded_batch(32, padded_shapes=([-1], []))이제 데이터가 이어지는 절에서 구현할 RNN 모델에 적합한 포맷이 되었다. 그전에 먼저 다음 절에서 특성 임베딩(embedding)에 대해 알아보자! 필수적인 것은 아니지만 단어 벡터의 차원을 줄여 주기 때문에 매우 권장되는 전처리 단계이다!