* 본 포스팅은 머신러닝교과서를 참조하여 작성되었습니다.
* https://github.com/rickiepark/python-machine-learning-book-3rd-edition
GitHub - rickiepark/python-machine-learning-book-3rd-edition: <머신 러닝 교과서 3판>의 코드 저장소
<머신 러닝 교과서 3판>의 코드 저장소. Contribute to rickiepark/python-machine-learning-book-3rd-edition development by creating an account on GitHub.
github.com
선형 회귀는 하나 이상의 특성과 연속적인 타깃 변수 사이의 관계를 모델링하는 것이 목적이다. 지도 학습의 다른 카테고리인 분류 알고리즘과 달리 회귀는 범주형 클래스 레이블이 아니라 연속적인 출력 값을 예측한다.
10.1.1 단순 선형 회귀
단순 선형 회귀는 하나의 특성(설명 변수(explanatory variable) x)과 연속적인 타깃(응답 변수(response variable) y) 사이의 관계를 모델링한다.

데이터에 가장 잘 맞는 이런 직선을 회귀 직선(regression line)이라고도 한다. 회귀 직선과 훈련 샘플 사이의 직선 거리를 오프셋(offset) 또는 예측 오차인 잔차(residual)라고 한다.
10.1.2 다중 선형 회귀
이번 절에서 소개한 선형 회귀처럼 특성이 하나인 특별한 경우를 단순 선형 회귀라고 한다. 당연히 선형 회귀 모델은 여러 개의 특성이 있는 경우로 일반화할 수 있다. 이를 다중 선형 회귀라고 한다.
10.2 주택 데이터셋 탐색
10.2.1 데이터프레임으로 주택 데이터셋 읽기
주택 데이터셋은 506개의 샘플이 있으며 특성은 다음과 같다.
- CRIM : 도시의 인당 범죄율
- ZN : 2만 5,000 평방 피트가 넘는 주택 비율
- INDUS: 도시에서 소매 업종이 아닌 지역 비율
- CHAS: 찰스 강 인접 여부(강 주변=1, 그 외=0)
- NOX: 일산화질소 농도(10ppm당)
- RM: 주택의 평균 방 개수
- AGE: 1940년 이전에 지어진 자가 주택 비율
- DIS: 다섯 개의 보스턴 고용 센터까지 가중치가 적용된 거리
- RAD: 방사형으로 뻗은 고속도로까지 접근성 지수
- TAX: 10만 달러당 재산세율
- PTRATIO: 도시의 학생-교사 비율
- B: 1000(Bk - 0.63) **2, 여기서 Bk는 도시의 아프리카계 미국인 비율
- LSTAT: 저소득 계층의 비율
- MEDV: 자가 주택의 중간 가격(1,000달러 단위)
주택 가격(MEDV)을 타깃 값으로 삼는다. 13개의 특성 중 하나 이상을 사용하여 이 값을 예측한다.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/rasbt/'
'python-machine-learning-book-3rd-edition/'
'master/ch10/housing.data.txt',
header=None,
sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS',
'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df.head()
10.2.2 데이터셋의 중요 특징 시각화
탐색적 데이터 분석(Exploratory Data Analysis, EDA)은 머신 러닝 모델을 훈련하기 전에 첫 번째로 수행할 중요하고 권장되는 단계이다.
먼저 산점도 행렬(scatterplot matrix)을 그려서 데이터셋에 있는 특성 간의 상관관계를 한 번에 시각화해 보자.
!pip install --upgrade mlxtend
import matplotlib.pyplot as plt
from mlxtend.plotting import scatterplotmatrix
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
scatterplotmatrix(df[cols].values, figsize=(10, 8), names=cols, alpha=0.5)
plt.tight_layout()
plt.show()

산점도 행렬을 사용하면 데이터가 어떻게 분포되어 있는지, 이상치를 포함하고 있는지 빠르게 확인할 수 있다. 예를 들어 RM과 주택 가격인 MEDV 사이에 선형적인 관계가 있다는 것을 알 수 있다. 또 오른쪽 맨 아래에서 MEDV의 히스토그램을 볼 수 있다. 이 데이터는 일부 이상치가 있지만 정규 분포 형태를 띠고 있다.
10.2.3 상관관계 행렬을 사용한 분석
상관관계 행렬(correlation matrix)을 만들어 변수 간의 선형 관계를 정령화하고 요약해 보자. 상관관계 행렬은 5장의 '주성분 분석을 통한 비지도 차원 축소' 절에서 본 공분산 행렬(covariance matrix)과 밀접하게 관련되어 있다.
직관적으로 생각하면 상관관계 행렬을 스케일 조정된 공분산 행렬로 생각할 수 있다. 사실 특성이 표준화되어 있으면 상관관계 행렬과 공분산 행렬이 같다.
상관관계 행렬은 피어슨의 상관관계 계수(Pearson product-moment correlation coefficient)를 포함하고 있는 정방 행렬이다. 이 계수는 특성 사이의 선형 의존성을 측정한다. 상관관계 계수의 범위는 -1 ~ 1 이다. r=1 이면 두 특성이 완벽한 양의 상관관계를 가진다. r = 0 이면 아무런 상관관계가 없다. r = -1 이면 완벽한 음의 상관관계를 가진다.
앞서 언급한 것처럼 피어슨의 상관관계 계수는 단순히 두 특성 x와 y 사이의 공분산(분자)을 표준편차의 곱(분모)으로 나눈 것이다.
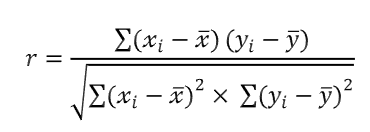
앞서 산점도 행렬로 그렸던 다섯 개의 특성에 넘파이 corrcoef 함수를 사용해 보자.
from mlxtend.plotting import heatmap
import numpy as np
cm = np.corrcoef(df[cols].values.T)
hm = heatmap(cm, row_names=cols, column_names=cols)
plt.show()

선형 회귀 모델을 훈련하려면 타깃 변수 MEDV와 상관관계가 높은 특성이 좋다. 이 상관관계 행렬을 살펴보면 타깃 변수 MEDV가 LSTAT와 상관관계가 높다.(-0.74). 산점도 행렬에서 보았던 LSTAT와 MEDV 사이 관계는 확실히 비선형적이다.
한편 RM과 MEDV 사이의 상관관계도 비교적 높다(0.7). 산점도 행렬에서 보면 이 두 변수가 선형 관계를 가지므로 RM이 선택하기 좋은 특성으로 보인다.
'소소하지만 소소하지 않은 개발 공부 > 머신 러닝 교과서' 카테고리의 다른 글
| [머신러닝교과서] 사이킷런을 사용한 k-평균 군집, KMeans, python (0) | 2023.01.06 |
|---|---|
| 10.4 RANSAC을 사용하여 안정된 회귀 모델 훈련, python (0) | 2022.12.23 |
| 8.2 BoW 모델 소개, 머신러닝교과서, python (0) | 2022.12.21 |
| 7. 다양한 모델을 결합한 앙상블 학습, 머신러닝교과서, python (0) | 2022.12.19 |
| 6.2 k-겹 교차 검증을 사용한 모델 성능 평가 (0) | 2022.12.14 |