* 본 포스팅은 머신러닝교과서를 참조하여 작성되었습니다.
* https://github.com/rickiepark/python-machine-learning-book-3rd-edition
GitHub - rickiepark/python-machine-learning-book-3rd-edition: <머신 러닝 교과서 3판>의 코드 저장소
<머신 러닝 교과서 3판>의 코드 저장소. Contribute to rickiepark/python-machine-learning-book-3rd-edition development by creating an account on GitHub.
github.com
7.1 앙상블 학습
앙살블 학습(ensemble learning)의 목표는 여러 분류기를 하나의 메타 분류기로 연결하여 개별 분류기보다 더 좋은 일반화 성능을 달성하는 것이다.

유명한 앙상블 방법 중 하나는 서로 다른 결정 트리를 연결한 랜덤 포레스트(random forest)이다. 아래 그림은 과반수 투표를 사용한 일반적인 앙상블 방법이다.

과반수 투표나 다수결 투표로 클래스 레이블을 예측하려면 개별 분류기의 예측 레이블을 모아 가장 많은 표를 받은 레이블을 선택한다.
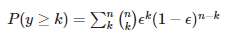
이상적인 앙상블 분류기와 다양한 범위의 분류기를 가진 경우와 비교하기 위해 파이썬으로 확률 질량 함수를 구현해 보자.
from scipy.special import comb
import math
def ensemble_error(n_classifier, error):
k_start = int(math.ceil(n_classifier / 2.))
probs = [comb(n_classifier, k) * error ** k * (1-error) ** (n_classifier - k)
for k in range(k_start, n_classifier + 1)]
return sum(probs)
ensemble_error(n_classifier = 11, error=0.25)
>> 0.03432750701904297
ensemble_error 함수를 구현한 후 분류기 에러가 0.0에서 1.0까지 걸쳐 있을 때 앙상블의 에러율을 계산해보자. 그다음 앙상블과 개별 분류기 에러 사이의 관계를 선 그래프로 시각화해 보자.
import numpy as np
import matplotlib.pyplot as plt
error_range = np.arange(0.0, 1.01, 0.01)
ens_errors = [ensemble_error(n_classifier=11, error=error) for error in error_range]
plt.plot(error_range, ens_errors,
label = 'Ensemble error',
linewidth=2)
plt.plot(error_range, error_range, linestyle='--', label='Base error', linewidth=2)
plt.xlabel('Base error')
plt.ylabel('Base/Ensemble error')
plt.legend(loc='upper left')
plt.grid(alpha=0.5)
plt.show()
앙상블의 에러 확률은 개별 분류기보다 항상 좋다. 다만 개별 분류기가 무작위 추측(<0.5)보다 성능이 좋아야 한다. y축은 분류기 에러(점선)와 앙상블 에러(실선)를 나타낸다.
'소소하지만 소소하지 않은 개발 공부 > 머신 러닝 교과서' 카테고리의 다른 글
| 10.1 선형회귀, 머신러닝교과서, python (1) | 2022.12.22 |
|---|---|
| 8.2 BoW 모델 소개, 머신러닝교과서, python (0) | 2022.12.21 |
| 6.2 k-겹 교차 검증을 사용한 모델 성능 평가 (0) | 2022.12.14 |
| 5.3 커널 PCA를 사용하여 비선형 매핑, 머신러닝교과서, python (0) | 2022.12.13 |
| 5.차원 축소를 사용한 데이터 압축, 머신러닝교과서, python (1) | 2022.12.11 |