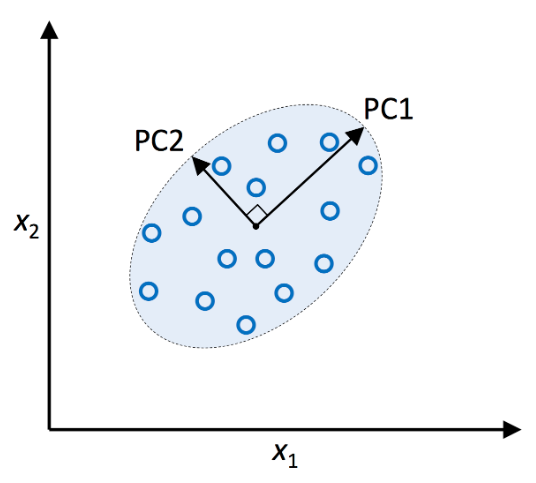
* 본 포스팅은 머신러닝교과서를 참조하여 작성되었습니다. * https://github.com/rickiepark/python-machine-learning-book-3rd-edition GitHub - rickiepark/python-machine-learning-book-3rd-edition: 의 코드 저장소 의 코드 저장소. Contribute to rickiepark/python-machine-learning-book-3rd-edition development by creating an account on GitHub. github.com 8.2.1 단어를 특성 벡터로 변환 사이킷런에 구현된 CounterVectorizer 클래슬르 사용하여 각각의 문서에 있는 단어 카운트를 기반으로 BoW 모델을..