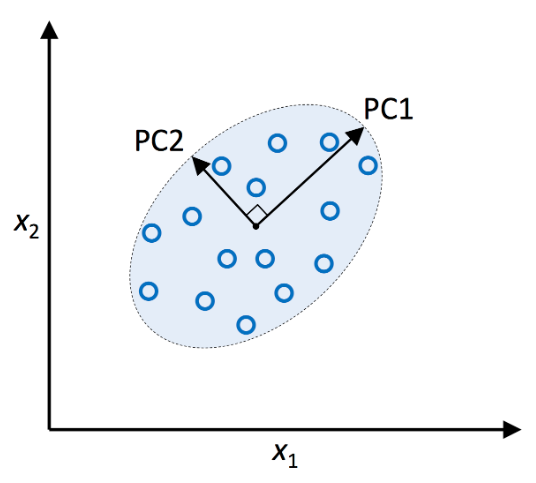
*본 포스팅은 머신러닝교과서를 참조하여 작성되었습니다. 5.3 커널 PCA를 사용하여 비선형 매핑 실전 애플리케이션에서는 비선형 문제를 더 자주 맞닥뜨린다. 이런 비선형 문제를 다루어야 한다면 PCA와 LDA 같은 차원 축소를 위한 선형 변형 기법은 최선의 선택이 아니다. 5.3.1 커널 함수와 커널 트릭 3장에서 커널 SVM에 관해 배운 것을 떠올려 보면 비선형 문제를 해결하기 위해 클래스가 선형으로 구분되는 새로운 고차원 특성 공간으로 투영할 수 있다. 즉, 커널 PCA를 통한 비선형 매핑을 수행하여 데이터를 고차원 공간으로 변환한다. 그 다음 고차원 공간에 표준 PCA를 사용하여 샘플이 선형 분류기로 구분될 수 있는 저차원 공간으로 데이터를 투영한다. 이 방식의 단점은 계산 비용이 아주 비싸다는 것..